

201405 - page 97
北京工商大学学报
(
社会科学版
)摇 摇 摇 摇 2014
年
摇
第
5
期
0郾 98,
可见模型对被解释变量的解释度很高
。
(
三
)
回归结果的分析
从回归的结果可以看出
,
受教育程度的高低
对寿险业的需求不存在显著的影响力
。
究其原
因
,
我国的高等教育中并没有对学生保险意识的
培养
,
也没有类似通过保险手段来规避风险的宣
传
,
大部分接受过高等教育的大学生对保险的理
解和中老年人没有差异
,
并没有对保险较为深刻
的认识
,
甚至有一些学生对保险的负面认识更加
深刻
。
社会保障覆盖率的高低也对寿险发展不存在
显著影响
,
这与我国社会保障的保障程度和保障
面有很大关系
。
由于我国目前社保覆盖面较窄且
保障程度较低
,
对于收入较高的人群不具有高端
保障的替代作用
,
因此有高端保险需求的消费者
依旧会在拥有社保的情况下购买商业保险
。
人均收入
、
金融产业比重
、
城镇化水平和人口
结构均对寿险业发展存在显著影响
。
其中
,
人均
收入
、
金融产业占比
、
城镇化水平和老年赡养比均
对寿险业有正向影响
。
人口结构因素中
,
少年抚
养比却对寿险需求有负向影响
。
这与部分学者的
结论相左
,
本文认为少儿抚养比的提高会加重劳
动人口的经济负担
,
从而压缩其他方面的支出
,
导
致其降低了寿险需求
,
而普遍的认为少儿抚养比
会增加寿险需求的观点
,
认为增加的需求为劳动
人口
,
为保证其对少儿的养育不受到未来自身风
险的影响而购买的寿险产品
。
本文认为
,
在目前
我国大部分人群还没有通过保险的方式来转嫁子
女养育风险的今天
,
少儿抚养比的提高对寿险产
品的抑制作用会多于促进作用
。
三
、
基于
shapley
值分解法的中国寿险业区
域发展差异分解
(
一
)
分解回归方程的设定
本文运用由
Shorrocks
提出的夏普利
( Shap鄄
ley)
值分解法来分解各个解释变量对区域寿险业
发展差异的影响贡献度
淤
,
先设定回归方程
。
在
实证分析中
,
本文构造了一个半对数模型的回归
方程
,
由于共同截距项
C
对寿险业区域发展差异
不会有影响
,
所以予以剔除
。
此外
,
平均受教育年
限和社会保障覆盖率这两个解释变量的系数不显
著
,
因此也不予使用
。
由此可得分解区域寿险业
发展差异的回归方程
:
LnDensity
it
= 19郾 386 73
Cyb
it
+ 0郾 988 811
LnJsr
it
+
1郾 446 913
Czb
it
+ 2郾 576 103
Lfb
it
- 1郾 852 353
Sfb
it
(
二
)
分解指标的选择
在夏普利值分解法的运用过程中
,
需要使用
反映区域发展差异的指标来分解不同解释变量对
被解释变量的影响贡献度
。
本文借鉴万广华
(2008)
对各种不平等度量指标的分析和比较
,
选
取了常用来反应收入差异的指标
Gini
系数
、
广义
熵指标
(GE
0
和
GE
1
)。
鉴于变异系数平方与收入
差距指标的转移原理相悖
,Atkinson
指数与
GE
指
数存在单调变换的关系
,
因此也予以省略
。
由于
所选取的三个指标分别对不同等级的收入水平变
化比较敏感
,
其中
Gini
系数对中等收入水平的变
化比较敏感
,GE
1
指数对上等收入水平的变化比
较敏感
,GE
0
指数对低等收入水平的变化比较敏
感
,
运用上述三个指标的计算平均值来表示各个
解释变量对被解释变量的平均贡献度比较准确与
稳定
。
在进行分解之前
,
先运用
Gini
系数
于
、
广义熵
指标
(GE
0
和
GE
1
)
盂
对中国寿险业区域发展差异
程度进行了分析
,
分别对
2003—2012
年的
30
个
省份的寿险区域发展差异情况进行了如图
1
的
列示
。
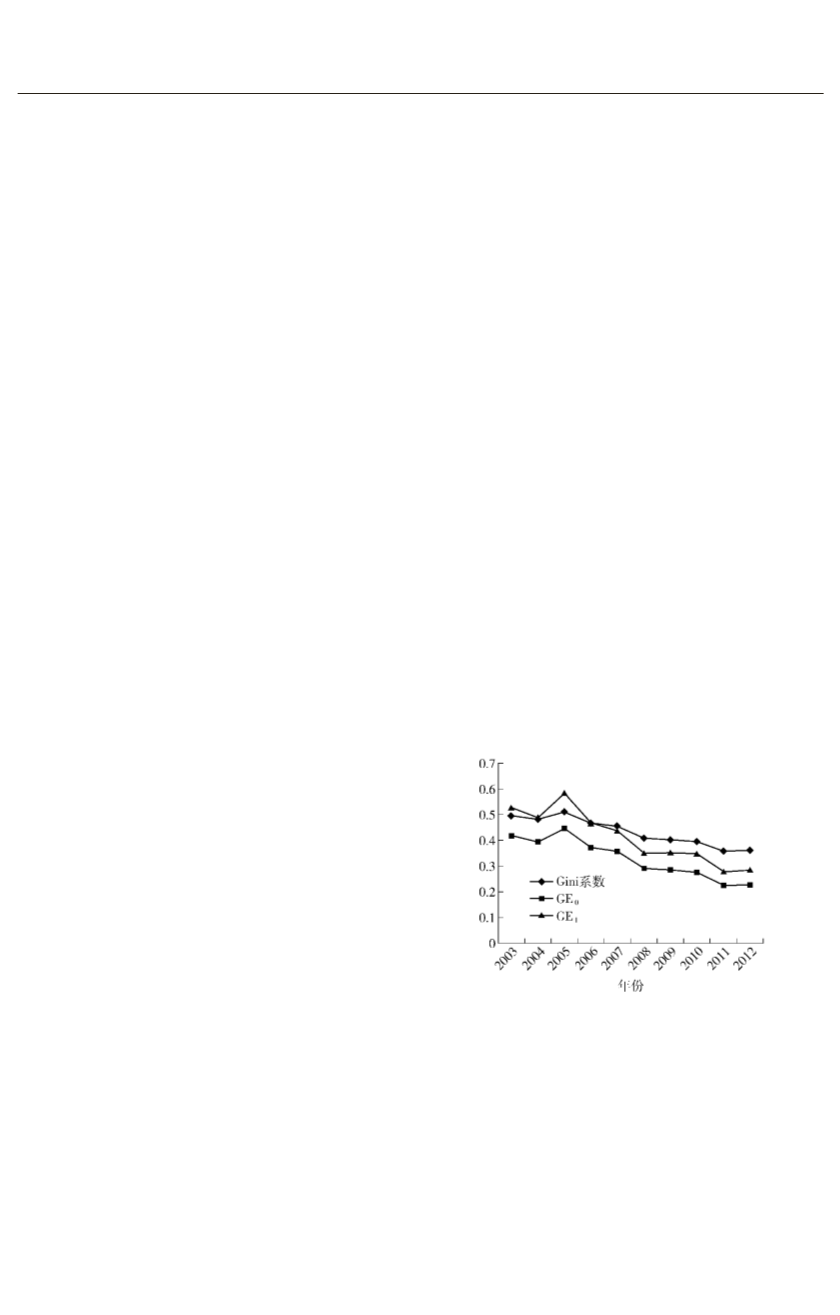
图
1摇 30
个省份的寿险发展差异
摇
由图
1
可见
,
近
10
年以来我国的寿险区域
发展差异在逐步地递减
,
除了在
2005
年出现了
一个短暂的差异增大以外
,
三个指标所显示的
发展趋势是总体一致的
。
虽然三个差异指标的
趋势是相似的
,
但解释变量在不同差异指标下
对寿险区域发展差异的贡献度却是略有差距
的
。
由表
2
可见
,
人均可支配收入在
2003—
2012
年的平均贡献度始终排在第一位
,
最高可
·29·
1...,87,88,89,90,91,92,93,94,95,96
98,99,100,101,102,103,104,105,106,107,...132
