
Page 42 - 北京工商大学学报社会科学版2018年第6期
P. 42
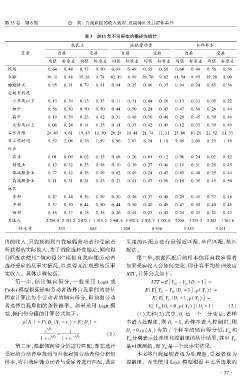
第 33 卷摇 第 6 期 章摇 莉: 自我雇佣的收入效应、发展特征及其群体差异
摇 摇 表 3摇 2013 年不同群体的描述性统计
农民工 城镇劳动者 全部样本
变量 自雇 受雇 自雇 受雇 自雇 受雇
均值 标准差 均值 标准差 均值 标准差 均值 标准差 均值 标准差 均值 标准差
性别 0郾 64 0郾 48 0郾 57 0郾 50 0郾 59 0郾 49 0郾 55 0郾 50 0郾 60 0郾 49 0郾 56 0郾 50
年龄 39郾 31 8郾 48 35郾 26 9郾 74 42郾 19 8郾 99 39郾 70 9郾 82 41郾 54 8郾 95 39郾 28 9郾 90
婚姻情况 0郾 95 0郾 21 0郾 79 0郾 41 0郾 94 0郾 25 0郾 86 0郾 35 0郾 94 0郾 24 0郾 85 0郾 36
受教育程度
摇 小学及以下 0郾 19 0郾 39 0郾 13 0郾 33 0郾 11 0郾 31 0郾 04 0郾 20 0郾 13 0郾 33 0郾 05 0郾 22
摇 初中 0郾 56 0郾 50 0郾 50 0郾 50 0郾 44 0郾 50 0郾 24 0郾 43 0郾 47 0郾 50 0郾 26 0郾 44
摇 高中 0郾 19 0郾 39 0郾 23 0郾 42 0郾 31 0郾 46 0郾 30 0郾 46 0郾 28 0郾 45 0郾 30 0郾 46
摇 大专及以上 0郾 06 0郾 24 0郾 14 0郾 35 0郾 14 0郾 35 0郾 42 0郾 49 0郾 12 0郾 33 0郾 39 0郾 49
工作年限 24郾 43 9郾 61 19郾 45 11郾 30 26郾 28 10郾 44 21郾 74 11郾 31 25郾 86 10郾 28 21郾 52 11郾 33
日工作时间 9郾 52 2郾 08 8郾 76 1郾 59 8郾 96 2郾 07 8郾 24 1郾 10 9郾 09 2郾 09 8郾 29 1郾 16
行业
摇 农业 0郾 01 0郾 09 0郾 02 0郾 15 0郾 08 0郾 26 0郾 01 0郾 12 0郾 06 0郾 24 0郾 02 0郾 12
摇 制造业 0郾 12 0郾 32 0郾 35 0郾 48 0郾 10 0郾 30 0郾 27 0郾 44 0郾 11 0郾 31 0郾 28 0郾 45
摇 低端服务业 0郾 77 0郾 42 0郾 38 0郾 49 0郾 62 0郾 49 0郾 24 0郾 43 0郾 65 0郾 48 0郾 25 0郾 44
摇 高端服务业 0郾 11 0郾 31 0郾 24 0郾 43 0郾 21 0郾 41 0郾 47 0郾 50 0郾 18 0郾 39 0郾 45 0郾 50
地区
摇 东部 0郾 27 0郾 44 0郾 38 0郾 49 0郾 30 0郾 46 0郾 37 0郾 48 0郾 29 0郾 45 0郾 37 0郾 48
摇 中部 0郾 57 0郾 50 0郾 44 0郾 50 0郾 44 0郾 50 0郾 40 0郾 49 0郾 47 0郾 50 0郾 40 0郾 49
摇 西部 0郾 16 0郾 37 0郾 18 0郾 38 0郾 26 0郾 44 0郾 23 0郾 42 0郾 24 0郾 43 0郾 22 0郾 42
月收入 2 709郾 8 2 183郾 2 2 072郾 1 1 515郾 2 2 901郾 6 3 532郾 4 2 303郾 7 1 783郾 8 2 858 3 275郾 3 2 282 1 761郾 6
样本量 353 885 1 200 8 556 1 553 9 441
得的收入,只能观测到自我雇佣劳动者和受雇者 采用的匹配方法有最邻近匹配、半径匹配、核匹
所获得的实际收入,为了消除选择性偏差,倾向得 配法。
分匹配法使用“倾向得分冶 模拟自我雇佣劳动者 第三步,根据匹配后的样本估算自我雇佣者
选择受雇的反事实情况,以获得无法观察的反事 如果受雇收入会如何变化,即计算平均处理效应
实收入。 具体步骤包括: ATT,计算公式如下:
第一步, 估计倾向得分, 一般采用 Logit 或 ATT = E[Y - Y | D = 1] =
1i 0i i
Probit 模型根据影响劳动者选择自我雇佣的特征 E{E[Y - Y | D = 1],p(X )} =
1i 0i i i
因素计算出每个劳动者的倾向得分,即预测劳动 E{E[Y | D = 1,p(X )] -
1i i i
者选择自我雇佣的条件概率。 如果采用 Logit 模 E[Y | D = 0,p(X )] | D = 1} (2)
0i i i i
型,倾向得分值的计算公式如下: (1)式和(2)式中,D 是一个二分变量,若样
i
p(X ) = P(D | X = x ) = E(D ) = 本进入处理组,则 D = 1,若样本进入控制组,则
i
i
i
i
i
i
e x i 茁 i 1 D = 0;p(X ) 为第 i 个样本的倾向得分值;Y 和
i
i
1i
= (1)
x i 茁 i - x i 茁 i
1 + e 1 + e Y 分别表示处理组和控制组的估计结果,其中 Y 1i
0i
第二步,根据倾向得分值进行匹配,即在选择 是可观测的,而 Y 是一个反事实结果。
0i
受雇的劳动者中找到与自我雇佣劳动者得分相似 本文将自我雇佣者视为处理组,受雇者视为
样本,将自我雇佣劳动者与受雇者进行匹配,通常 控制组。 首先使用 Logit 模型根据本文所选取的
· 3 7 ·